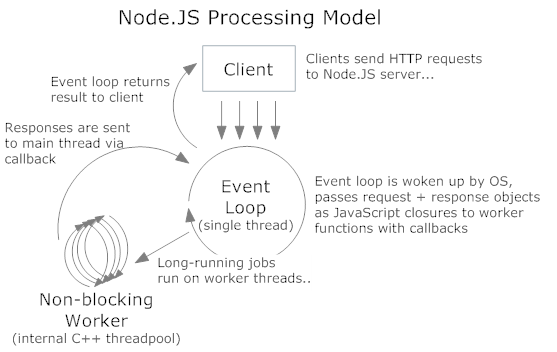
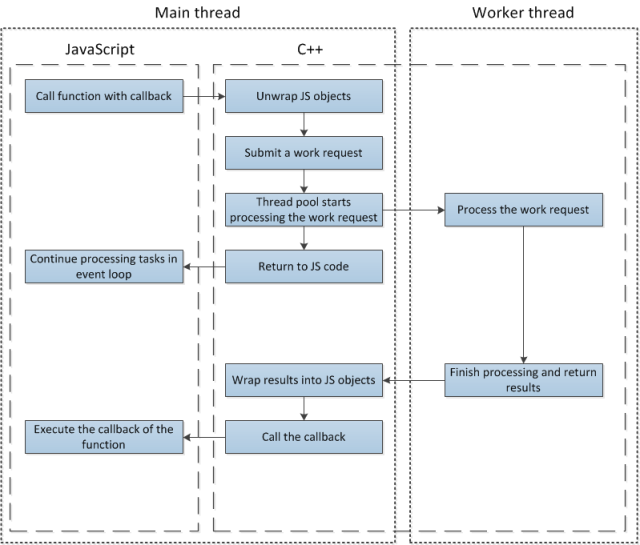
As explain in my previous posts, Event Loop is single threaded. If a code spend too much time in it, event loop becomes a botleneck, callbacks and events processing are delayed. An easy solution is to split the code into “chunks”: event loop thread process a chunk of code, then callbacks, then events, then another chunks then callbacks then events, and so on. For sure, such splitted code complets slower than one-block code, but at least the whole application stay reactive.
Node provides 2 means that allow code “chunking” setImmediate and process.nextTick. For using them properly one need to understand how they fit in the event loop and how they interact with callbacks and events processing.
First example
setTimeout( () => {
console.log('Timer 1');} ,
0
);
setImmediate( () => {
console.log('Immediate 1');
});
setImmediate( () => {
console.log('Immediate 2');
});
process.nextTick( () => {
console.log('Next tick 2');
});
setTimeout( () => {
console.log('Timer 2'); },
0);
(Timers are also in event loop, so I added them to obtain a better overview of event loop iteration)
With a Nodejs 4.x, this produces the following output:
Next tick 2
Timer 1
Timer 2
Immediate 1
Immediate 2
😯 Outputs does not follow the code order. And no mater the instructions order would be, the outputs would be the same. This spots the way an event loop iteration behaves :
- First, ticks and callback are excuteded
- Then timers are proceeded
- And finally the events and setImmediate are proceeded.
Do you see in what nextTick and setImmediate differs ?
With nextTick, the code is executed at the begin of the iteration, thus it delays events processing. With setImmediate, the code is executed at the end and so it is delayed by the callbacks and timers but does not delay the events to be processing. Now, up to you to see what is your priority.
Second exemple
'use strict';
setTimeout( () => {
console.log('Timer 1');
}, 0);
setImmediate( () => {
console.log('Immediate 1');
setImmediate( () => {
console.log('Immediate from immeditate 1');
});
process.nextTick( () => {
console.log('Next tick from Immediate 1');
});
setTimeout( () => {
console.log('Timer from Immediate 1');},
0);
});
process.nextTick( () => {
console.log('Next tick 1');
});
setImmediate( () => {
console.log('Immediate 2');
});
process.nextTick( () => {
console.log('Next tick 2');
});
This produces the outputs:
Next tick 1
Next tick 2
Timer 1
Immediate 1
Immediate 2
Next tick from Immediate 1
Timer from Immediate 1
Immediate from immeditate 1
Here, no suprise: the first event loop iteration executes ticks, timers and setImmediate, then the second iteration executes the ticks, timers and setImmediate added in the first setImmediate. But when one do the same with nextTick, there’s a surprise…
Third example
'use strict';
setTimeout( () => {
console.log('Timer 1');
}, 0);
setImmediate( () => {
console.log('Immediate 1');
});
process.nextTick( () => {
console.log('Next tick 1');
process.nextTick( () => {
console.log('Next tick from next tick 1');
});
setImmediate( () => {
console.log('Immediate from next tick 1');
});
setTimeout( () => {
console.log('Timer from next tick 1');},
0);
});
setImmediate( () => {
console.log('Immediate 2');
});
process.nextTick( () => {
console.log('Next tick 2');
});
This leads to the output:
Next tick 1
Next tick 2
Next tick from next tick 1
Timer 1
Timer from next tick 1
Immediate 1
Immediate 2
Immediate from next tick 1
Ticks, timers and setImmediate added in the nextTick are executed in the same iteration, thus the tick “tick from next tick 1” execution delay setImmediate and events processing. And if it would call some other nexTick, those last would also been processing in the event loop and would also delay event processing, and so on…
Conclusion
One can “chunks” his code using setImmediate or nextTick depending on its priority (chunked code to be executed before or after events). But when it comes to recursivity (chunked code using setImmediate/nextTick to execute code which also call setImmediate/nexTick), one should avoid nextTick, because this would postponed events processing and would prevent NodeJS to behave reactively.
This conclude my series about NodeJS overview. My next post will be about how to use mongoose in an optimized way.
See you and have a nice code 🙋